Jaeger Tracing пример на Django
Мини-лаборатория для исследования производительности узких мест в Django с помощью Jaeger, Redis и PostgreSQL.
⚙️ Стек
- Django
- Redis
- PostgreSQL
- Jaeger (OpenTelemetry)
- Docker Compose
📦 Установка
git clone git@gitlab.thenextgen.store:infra/jaeger-otel-django-example.git
cd jaeger-otel-django-example
git checkout tutorial
docker compose up -d db redis
docker compose run web python manage.py migrate
docker compose down --remove-orphans && docker compose up
Открыть http://127.0.0.1:8000
Генерируем один миллион записей в бд
Останавливаем все контейнеры:
docker compose down --remove-orphans
Добавляем пакет в requiremens.txt для генерации фейковых данных:
Faker
Создаем management таску todos/management/commands/gen_tasks.py:
from django.core.management.base import BaseCommand
from django.db import transaction
from todos.models import Task
from faker import Faker
fake = Faker()
class Command(BaseCommand):
help = "Generate N fake tasks"
def add_arguments(self, parser):
parser.add_argument("count", type=int, help="How many tasks")
def handle(self, *args, count, **kwargs):
CHUNK = 10_000 # bulk size
created = 0
while created < count:
batch = [
Task(title=fake.sentence(nb_words=6))
for _ in range(min(CHUNK, count - created))
]
with transaction.atomic():
Task.objects.bulk_create(batch, CHUNK)
created += len(batch)
self.stdout.write(f"-> {created}/{count}")
Запускаем все и ребилдим докер образ django сервиса:
docker compose up -d --build
Непосредственная генерация данных:
docker compose run web python manage.py gen_tasks 1000000
Подключаем opentelemetry и jaeger сервис
Обновляем docker-compose.yml:
services:
jaeger:
image: jaegertracing/all-in-one:1.54
ports:
- "16686:16686" # UI
- "4317:4317" # OTLP gRPC
web … ← внутри web-контейнера появится env-переменная
environment:
…
- OTEL_EXPORTER_OTLP_ENDPOINT=http://jaeger:4317
Добавляем пакеты opentelemetry в requirements.txt для инструментации Django:
opentelemetry-api
opentelemetry-sdk
opentelemetry-exporter-otlp
opentelemetry-instrumentation-django
opentelemetry-instrumentation-redis
Редактируем core/setting.py, нужно добавить следующее:
from opentelemetry import trace
from opentelemetry.sdk.resources import SERVICE_NAME, Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.instrumentation.django import DjangoInstrumentor
from opentelemetry.instrumentation.redis import RedisInstrumentor
# 1. включаем авто-инструментацию
DjangoInstrumentor().instrument()
RedisInstrumentor().instrument()
# 2. задаём provider + экспорт в Jaeger
trace.set_tracer_provider(
TracerProvider(
resource=Resource.create({SERVICE_NAME: "django-todo"})
)
)
span_processor = BatchSpanProcessor(
OTLPSpanExporter(endpoint=os.getenv("OTEL_EXPORTER_OTLP_ENDPOINT"))
)
trace.get_tracer_provider().add_span_processor(span_processor)
TRACER = trace.get_tracer(__name__)
Снова ребилдим и запускаем все после добавления пакетов:
docker compose down --remove-orphans && docker compose up --build
Снова открываем http://127.0.0.1:8000, страница будет лагать и может 9-12 секунд открываться из-за отображения 1 миллиона записей.
Переходим в Jaeger UI http://127.0.0.1:16686 Выбираем нужный Service. Нам интересны трассировки нашего django приложения, а не самого jaeger:
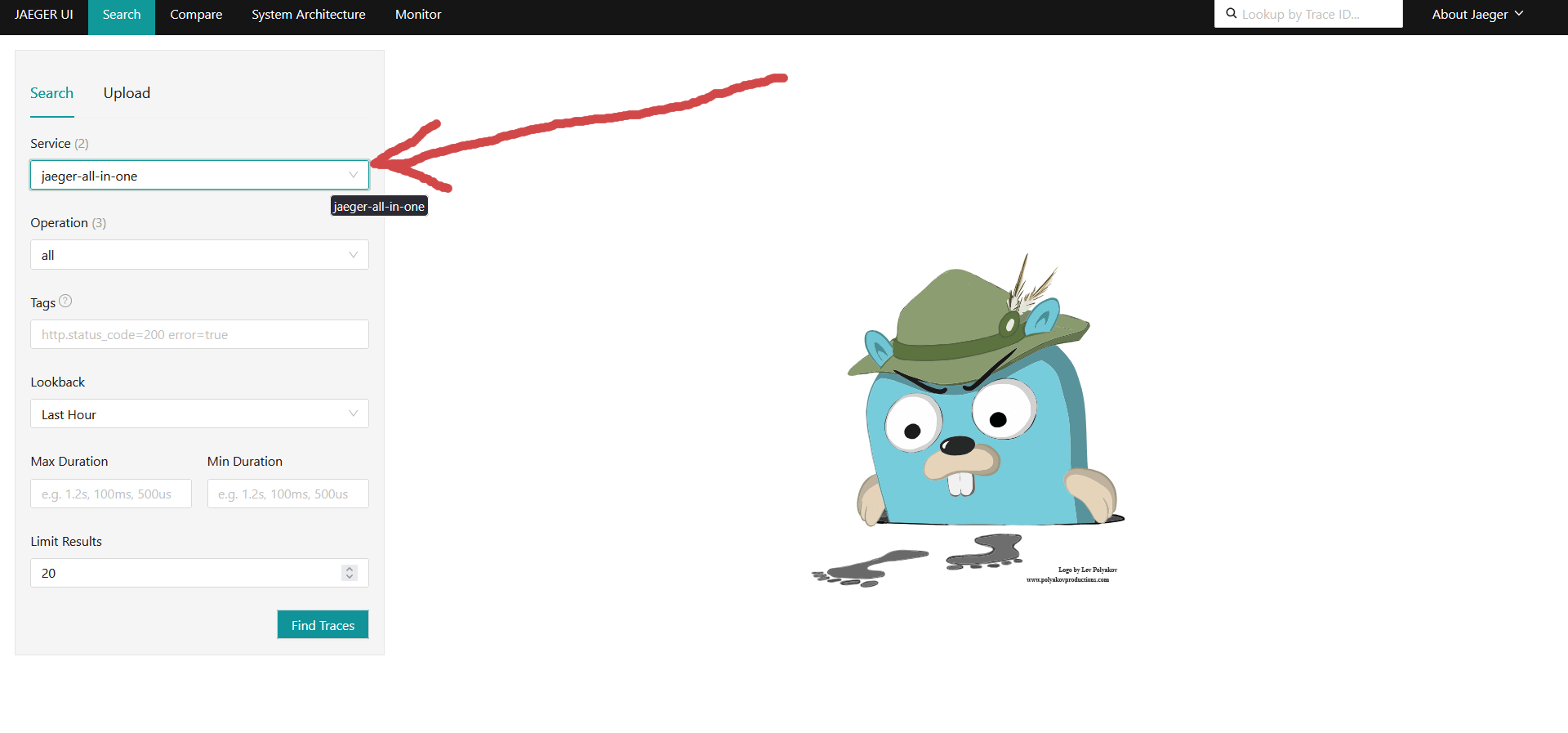
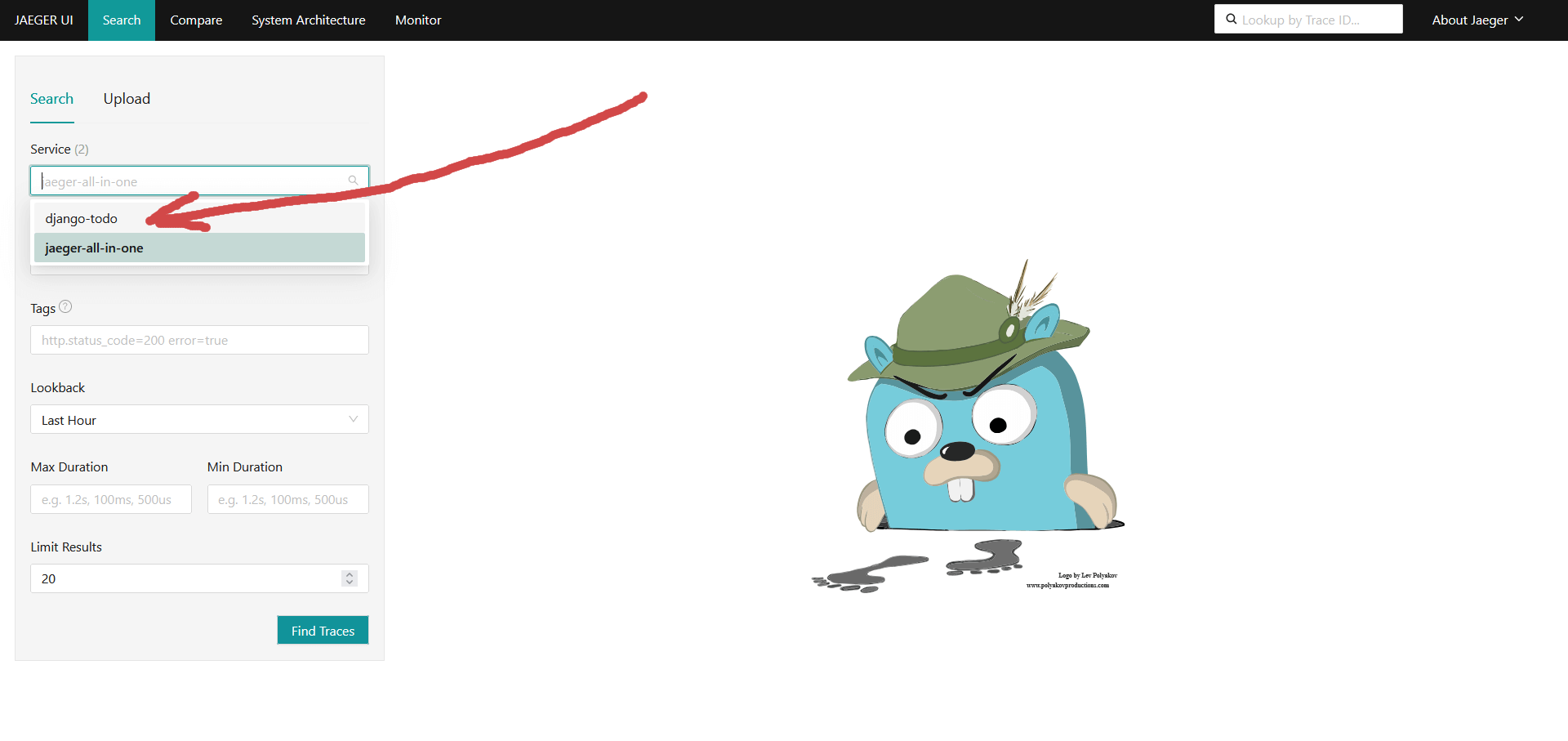
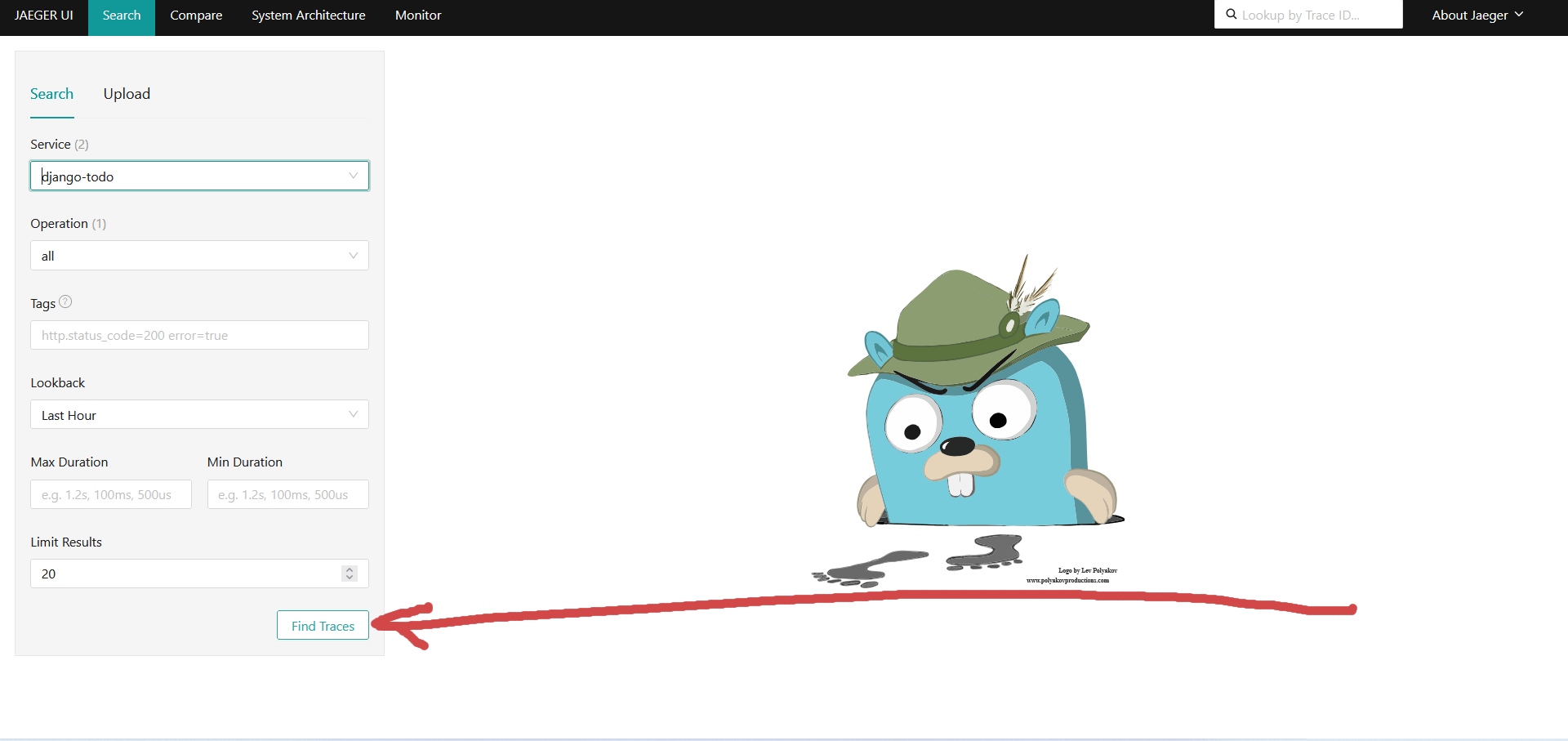
Жмакаем Find Traces:
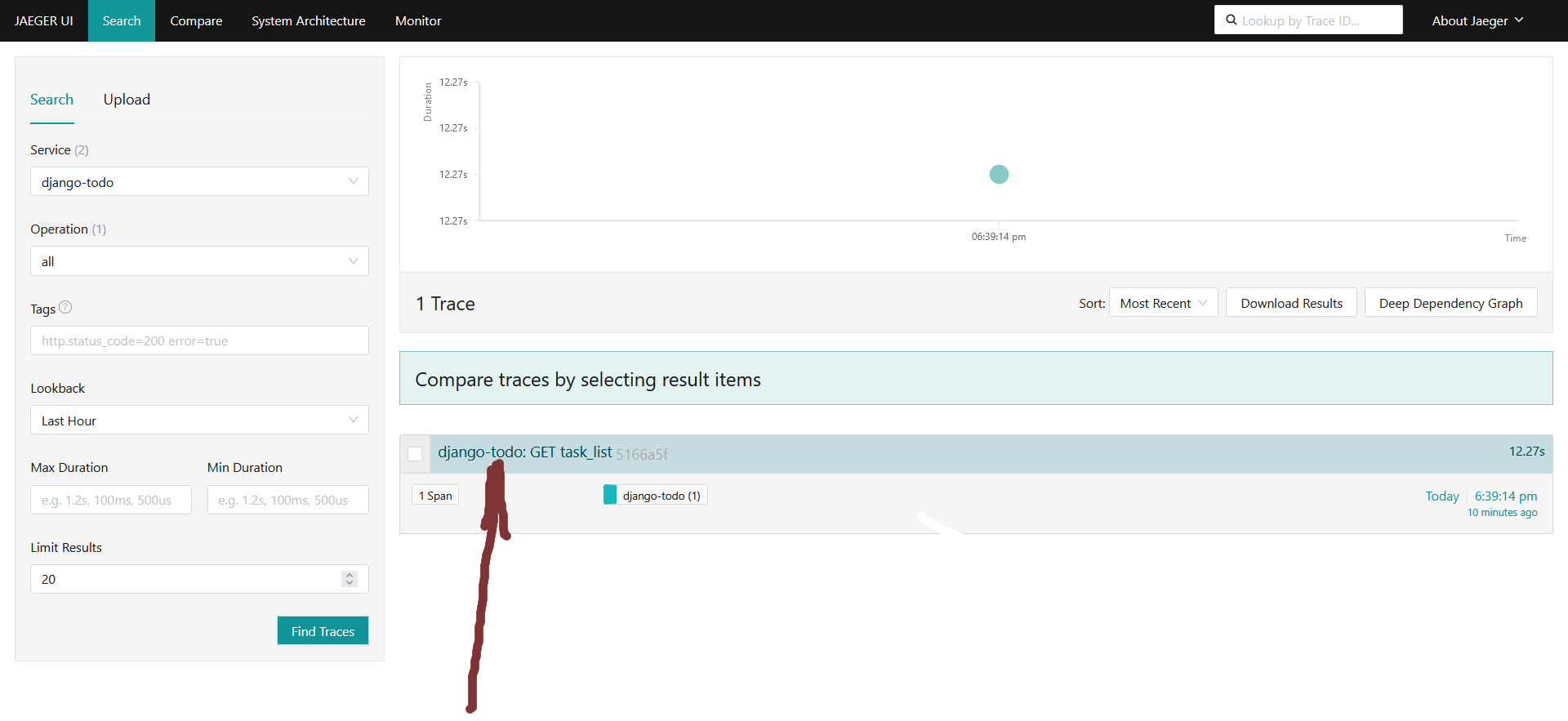
Видим наш трейс на 12 с лишним секунд, автозахват произошел благодаря ранее включенной автоинструментации, тыкаем на него как показано на картинке:
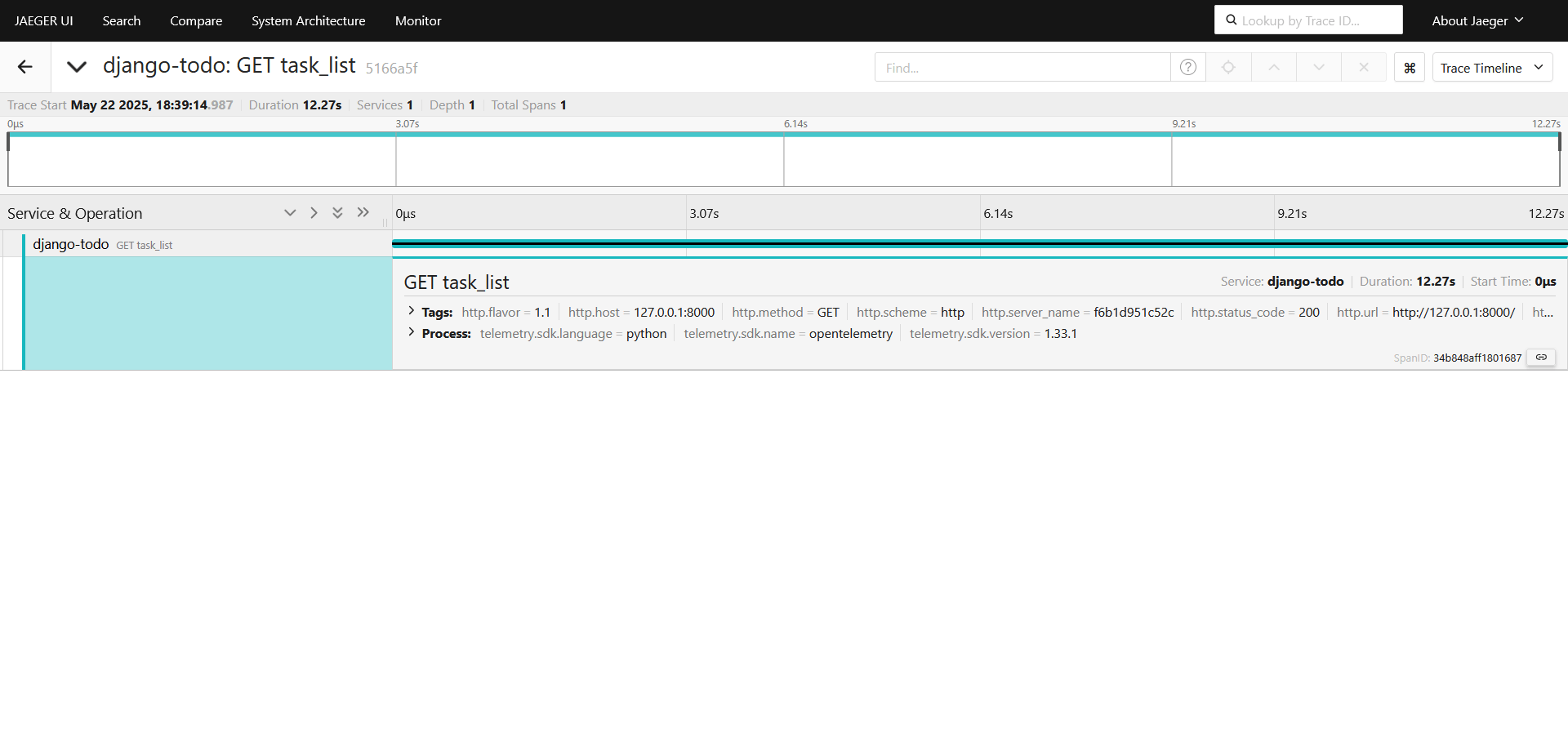
Не очень информативно, что же внутри конкретно тормозит, подключаем автоинструментацию postgres, добавим пакет opentelemetry для psycopg2, редактируем requirements.txt:
opentelemetry-instrumentation-psycopg2
Редактируем core/settings.py:
from opentelemetry.instrumentation.psycopg2 import Psycopg2Instrumentor
Psycopg2Instrumentor().instrument()
Перезапускаем и ребилдим web сервис, чтобы подтянуть изменения в requirements.txt:
docker compose down --remove-orphans && docker compose up --build
Снова открываем http://127.0.0.1:8000 и после http://127.0.0.1:16686, ищем трейсы из раздела Operations:
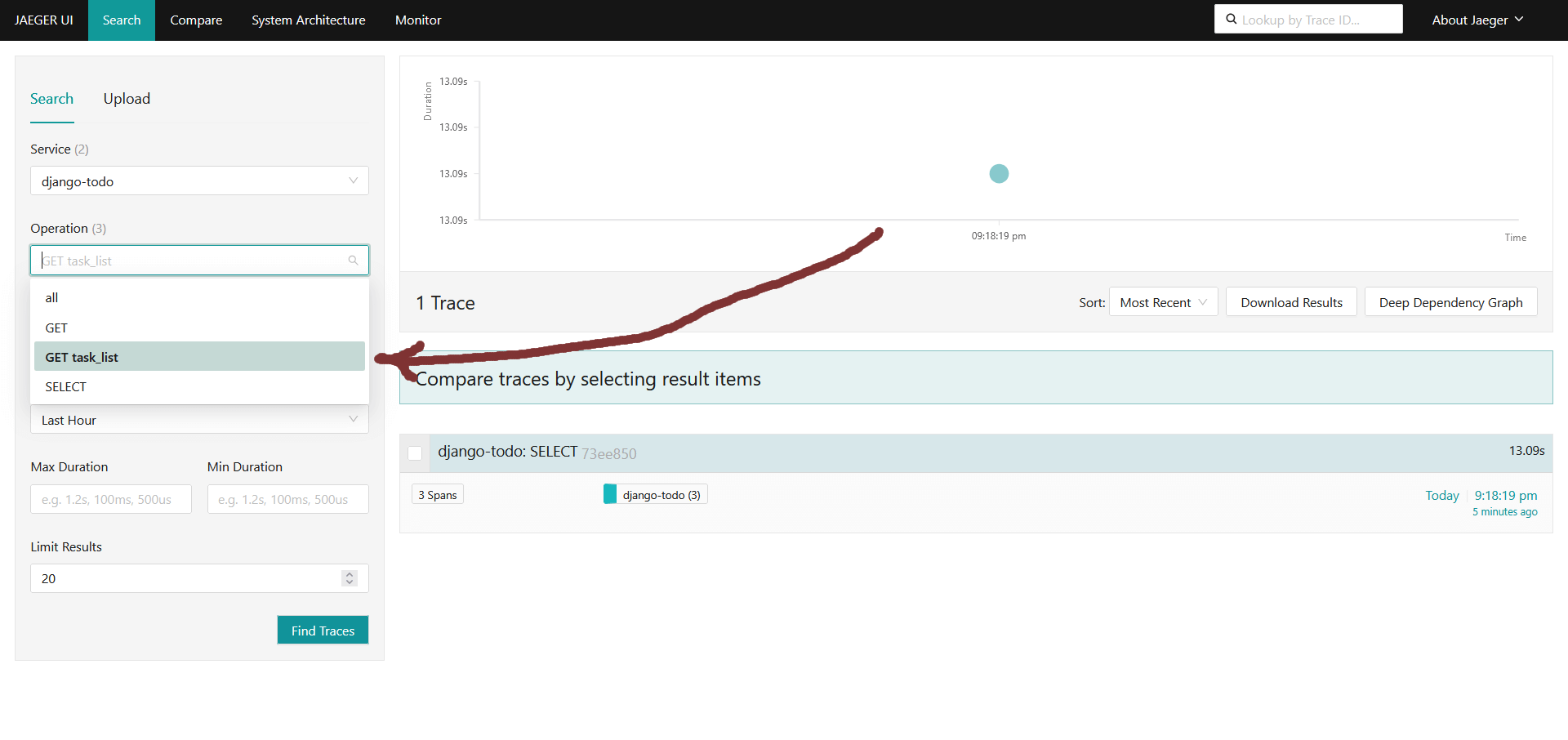
Переходим в свежий последний трейс и смотрим его:
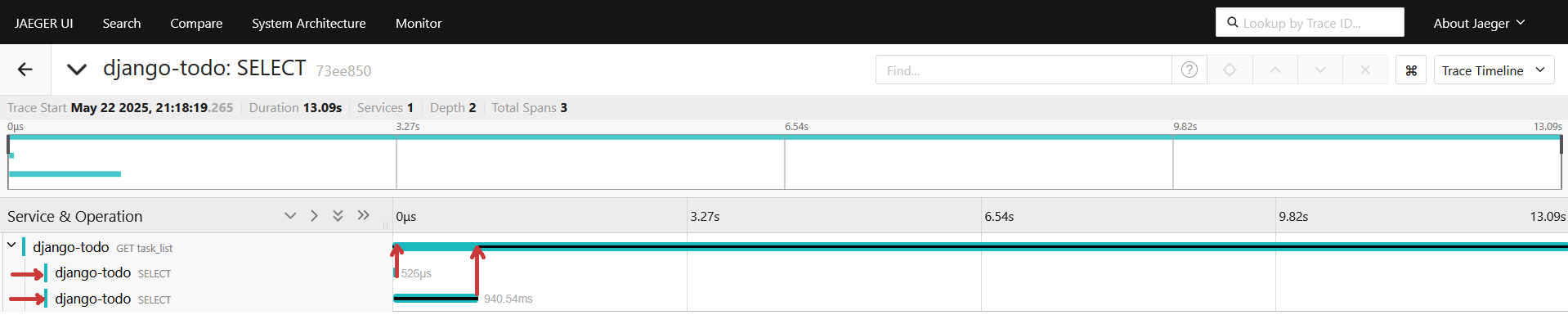
После включения автоинструментации видим два select-а, развернем их, видим первый запрос получает timezone и длится 526 микросекунд( не путать с миллисекундами в интерфейсе jaeger), второй наш тяжеленький на получение миллион строк занимает 940мс(миллисекунд):
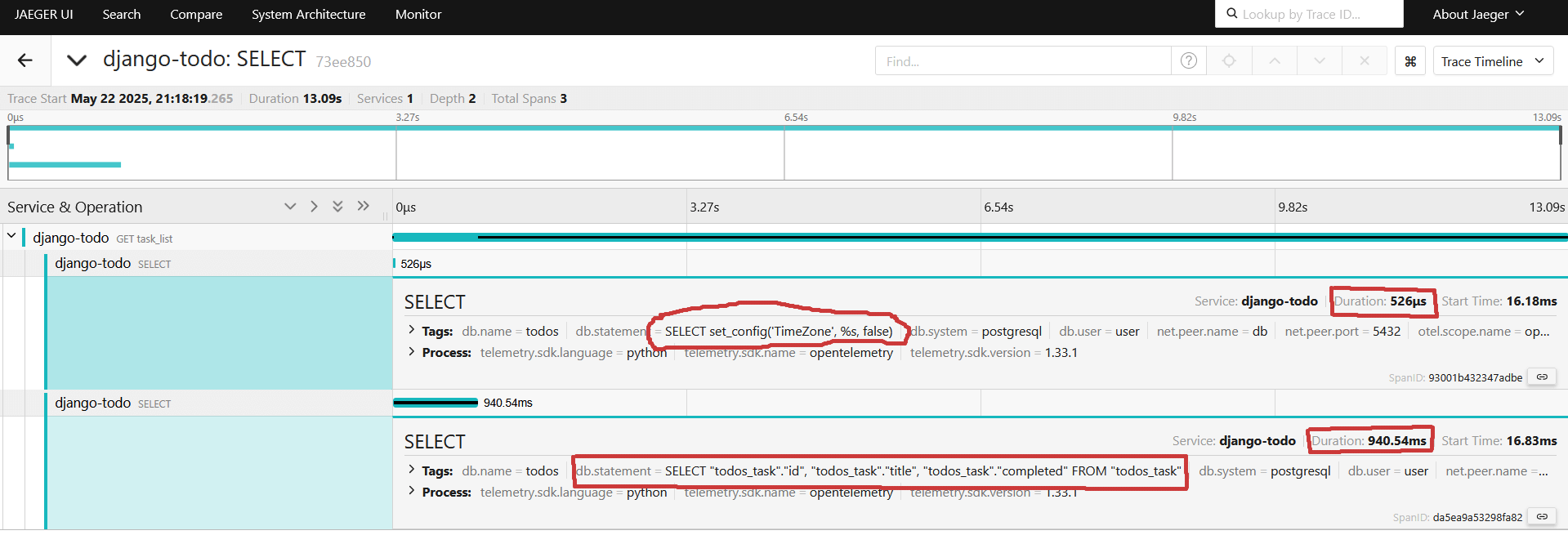
С запросами стало понятнее, что происходит, но остается один жирный кусок, который что-то делает больше 12 секунд, и средства автоинструментаций уже недостаточно, чтобы понять что происходит:
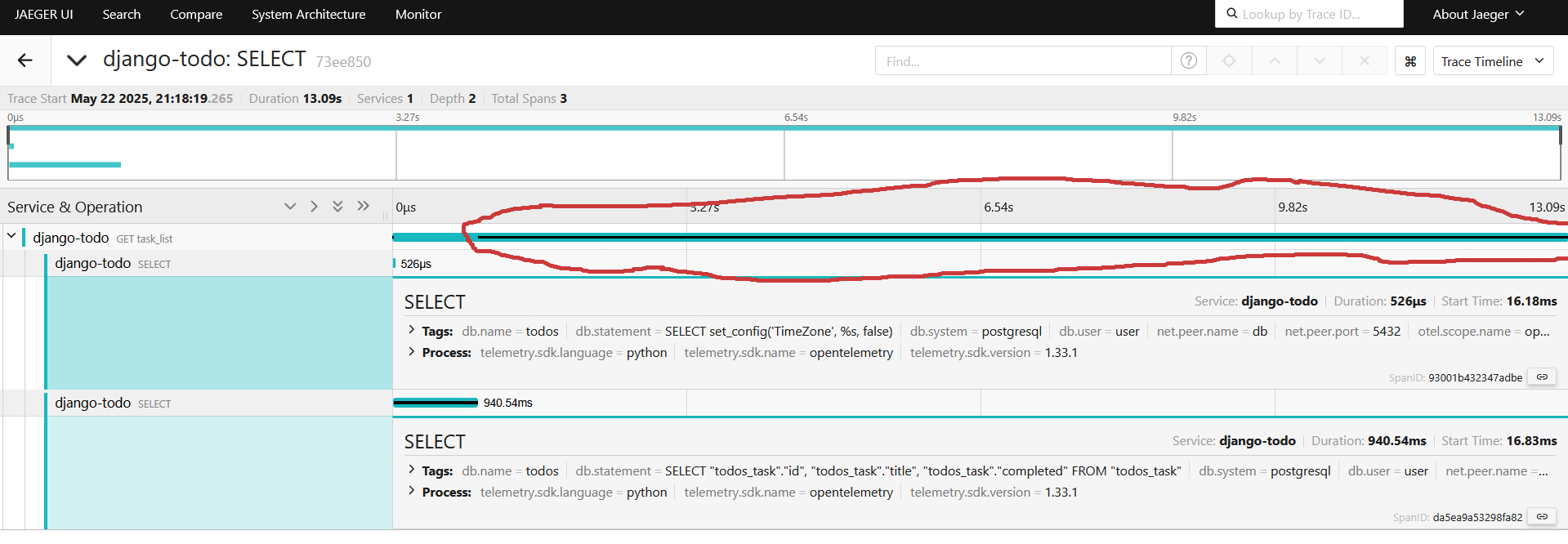
Открываем todos/view.py:
from django.shortcuts import render, redirect
from django.http import JsonResponse
from .models import Task
def task_list(request):
q = request.GET.get("q", "")
if q:
tasks = Task.objects.filter(title__icontains=q)
else:
tasks = Task.objects.all()
return render(request,'task_list.html',{'tasks':tasks, 'q': q})
def add_task(request):
if request.method=='POST':
title=request.POST.get('title')
if title:
Task.objects.create(title=title)
return redirect('task_list')
return redirect('task_list')
def api_tasks(request):
return JsonResponse(list(Task.objects.values()), safe=False)
Добавляем созданный TRACER из settings:
from django.conf import settings
TRACER = settings.TRACER
Меняем task_list метод:
def task_list(request):
with TRACER.start_as_current_span("task_list_common"):
q = request.GET.get("q", "")
if q:
tasks = Task.objects.filter(title__icontains=q)
return render(request,'task_list.html',{'tasks':tasks, 'q': q})
else:
tasks = Task.objects.all()
return render(request,'task_list.html',{'tasks':tasks, 'q': q})
Ребилд и перезапуск:
docker compose down --remove-orphans && docker compose up --build
Снова открываем http://127.0.0.1:8000, после http://127.0.0.1:16686, и открываем свежий трейс:
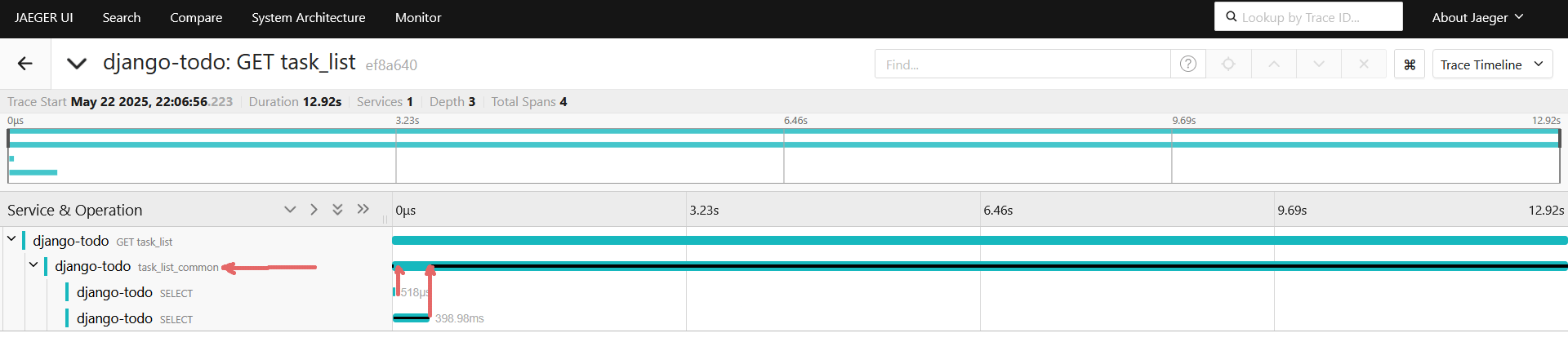
Появился новый общий span, который захватывает и отдачу всех миллионов объектов и поиск, если им воспользуются и рендер шаблона. Средства автоинструментации определили его как дочерний спан, для метода GET task_list. Теперь изменим код, чтобы спаны были разные и для выдачи всех объектов, поиска и рендера шаблона:
def task_list(request):
q = request.GET.get("q", "").strip()
trace_name = f"task_list_all" if not q else f"task_list_search"
with TRACER.start_as_current_span(trace_name) as span:
if q:
tasks = Task.objects.filter(title__icontains=q)
else:
tasks = Task.objects.all()
with TRACER.start_as_current_span(f"render_template") as render_span:
response = render(request,'task_list.html',{'tasks':tasks, 'q': q})
return response
Ребилд и перезапуск:
docker compose down --remove-orphans && docker compose up --build
Снова открываем http://127.0.0.1:8000, после http://127.0.0.1:16686, и открываем свежий трейс:
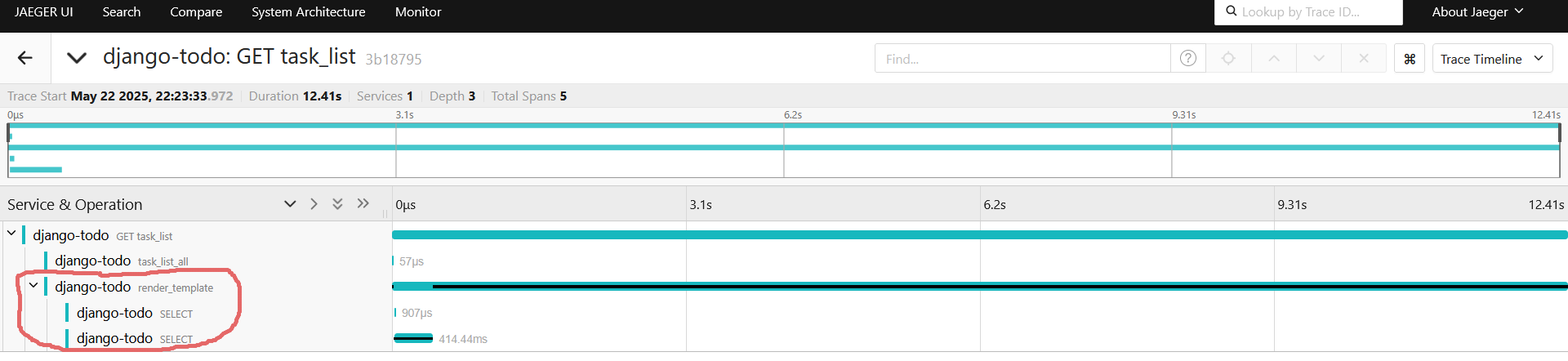
Ух, давно на Django программировал, для меня стало неожиданностью, что в спане task_list_all ленивые объекты создаются, а фактически запросы sql происходят в момент render шаблона(если быть точнее в момент обращения к объекту).
Попробуем кэширование в лоб, редактируем todos/view.py
from django.core.cache import cache
import hashlib
def task_list(request):
q = request.GET.get("q", "").strip()
trace_name = "task_list_all" if not q else "task_list_search"
# создаем уникальный ключ (например: task_list::all или task_list::search::<hash_q>)
if q:
key = f"task_list::search::{hashlib.md5(q.encode()).hexdigest()}"
else:
key = "task_list::all"
with TRACER.start_as_current_span(trace_name) as span:
tasks = cache.get(key)
if tasks is None:
if q:
tasks = list(Task.objects.filter(title__icontains=q))
else:
tasks = list(Task.objects.all())
cache.set(key, tasks, timeout=60) # кэш на 60 секунд
with TRACER.start_as_current_span("render_template") as render_span:
response = render(request, 'task_list.html', {'tasks': tasks, 'q': q})
return response
Автоинструментацию редиса мы включили в самом начале статьи, так что спан должен поймать что происходит на стороне редиса. Перезапускаем, снова снимаем спан и смотрим:
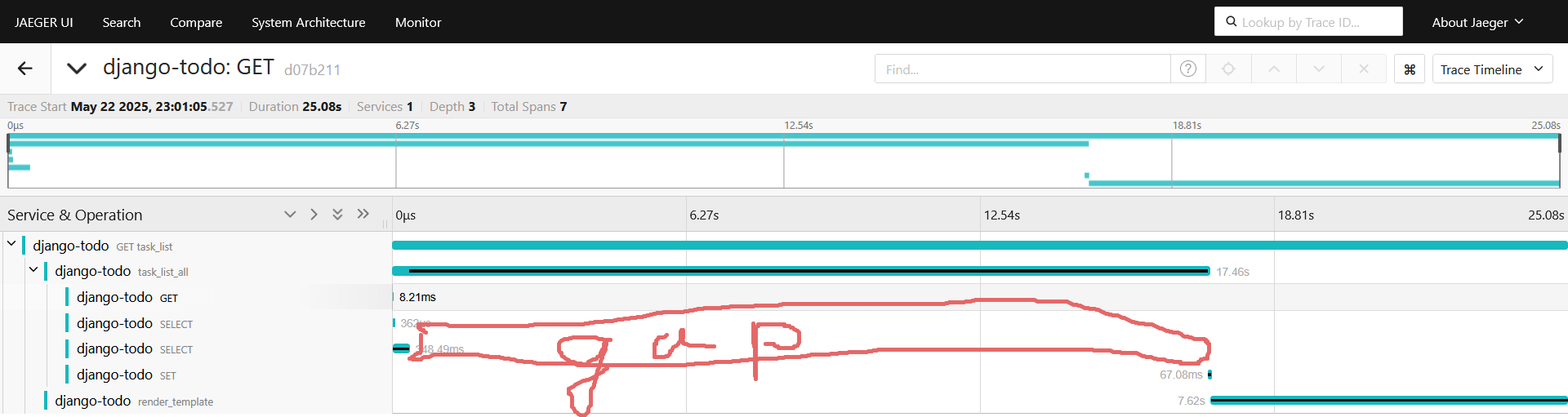
Поздравляю! Мы только что увеличили latency наивным подходом к кэшированию, подозреваю, что дело в tasks = list(Task.objects.all()), создание списка на миллион объектов. Попробуем под это дело завести отдельный дочерний спан:
with TRACER.start_as_current_span(trace_name) as span:
tasks = cache.get(key)
if tasks is None:
if q:
tasks = list(Task.objects.filter(title__icontains=q))
else:
with TRACER.start_as_current_span("tasks_list_creation"):
tasks = list(Task.objects.all())
cache.set(key, tasks, timeout=5*60) # кэш на 5 минут
Смотрим новый спан:
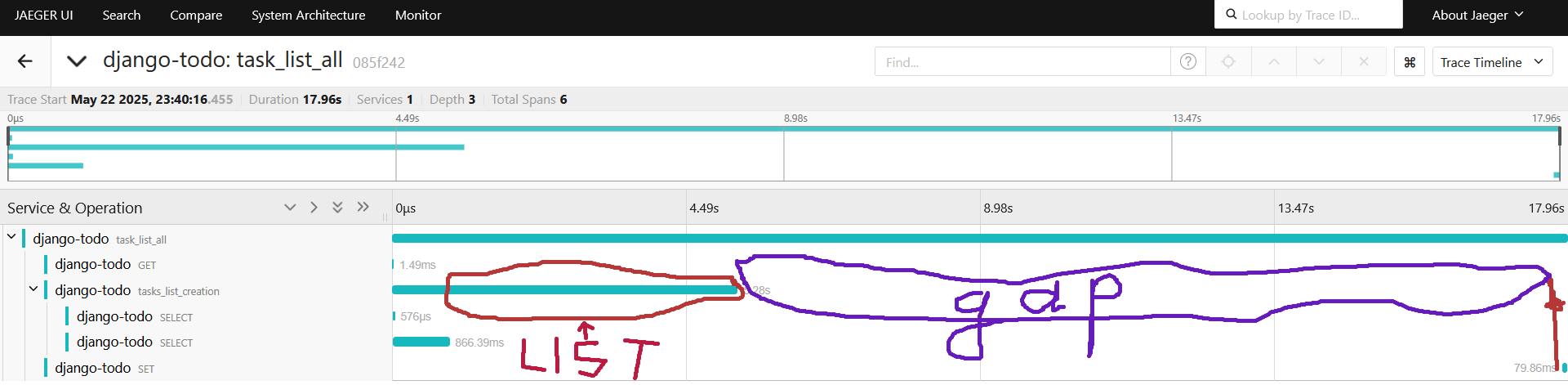
Опять есть пустое непокрытое место, попробуем и его покрыть спаном:
with TRACER.start_as_current_span(trace_name) as span:
tasks = cache.get(key)
if tasks is None:
if q:
tasks = list(Task.objects.filter(title__icontains=q))
else:
with TRACER.start_as_current_span("tasks_list_creation"):
tasks = list(Task.objects.all())
with TRACER.start_as_current_span("redis_serialization"):
cache.set(key, tasks, timeout=5*60) # кэш на 5 минут
Спан ловит пустое место:
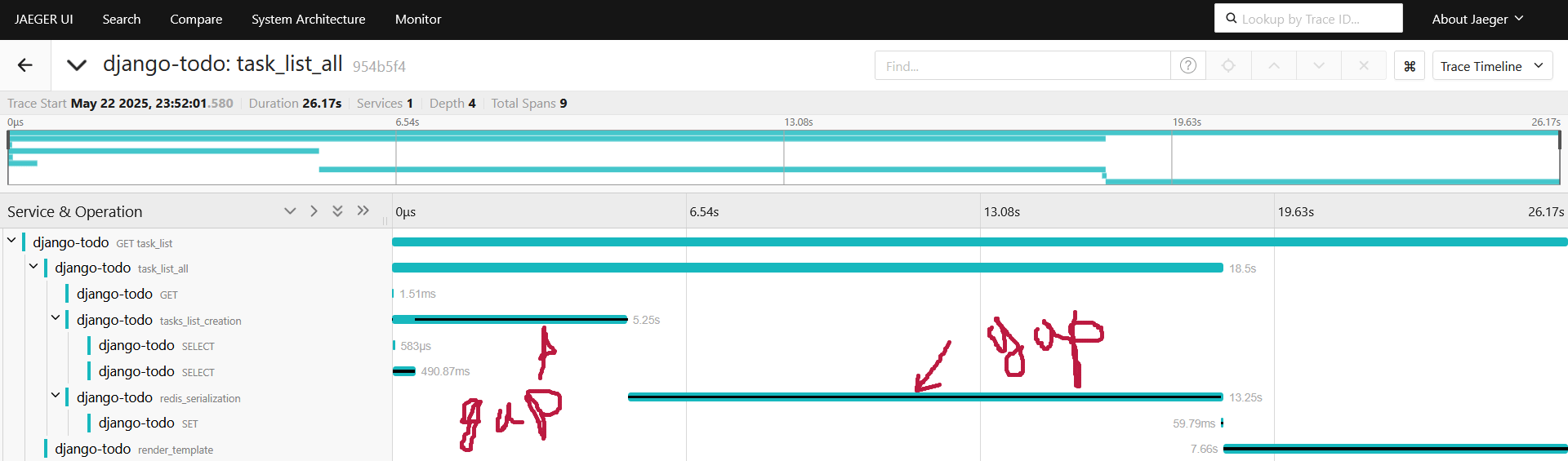
Пробуем оптимизации, грузим из Task только id, title, completed, а не пытаемся запихнуть весь Python object в список:
--- tasks = list(Task.objects.all())
+++ tasks = list(Task.objects.values("id", "title", "completed"))
Смотрим спаны:
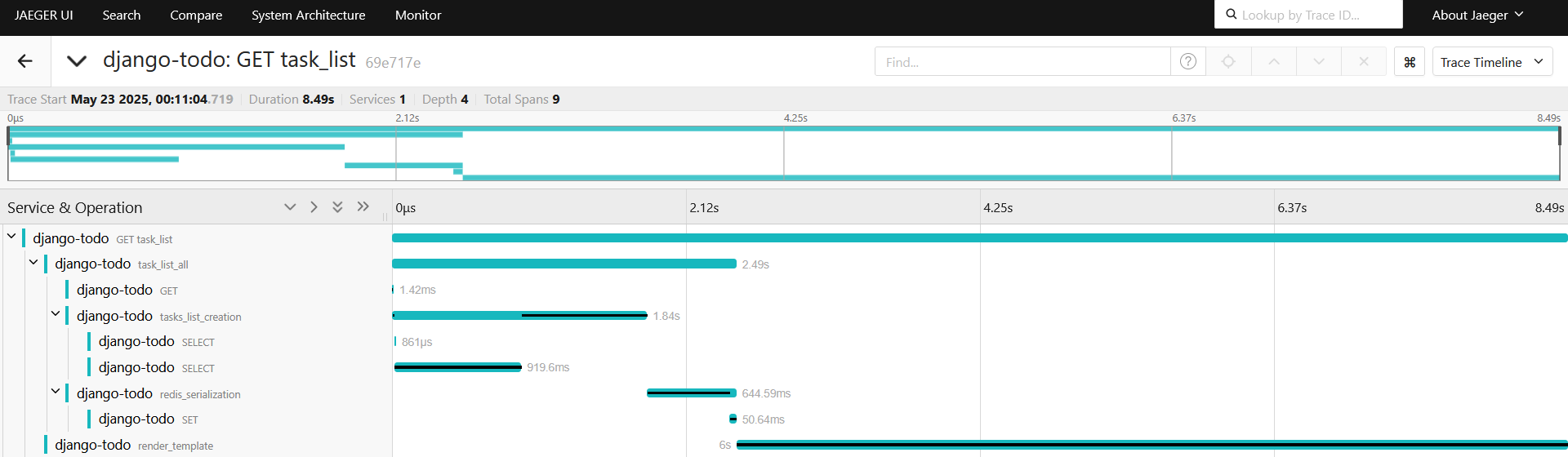
Формирование списка после sql 1.84 секунды вместо 5.25 ранее, ~3x быстрее. Передача списка в редис 644мс вместо 13.25 секунд ранее ~20x быстрее.
Пробуем перейти на json вместо pickle:
import json
import json
import hashlib
from django.core.cache import cache
from django.shortcuts import render
from .models import Task
from django.conf import settings
TRACER = settings.TRACER
def task_list(request):
q = request.GET.get("q", "").strip()
trace_name = "task_list_all" if not q else "task_list_search"
if q:
key = f"task_list::search::{hashlib.md5(q.encode()).hexdigest()}"
else:
key = "task_list::all"
with TRACER.start_as_current_span(trace_name) as span:
cached = cache.get(key)
if cached:
with TRACER.start_as_current_span("redis_deserialization"):
tasks = json.loads(cached)
else:
if q:
tasks = list(Task.objects.filter(title__icontains=q).values("id", "title", "completed"))
else:
with TRACER.start_as_current_span("tasks_list_creation"):
tasks = list(Task.objects.values("id", "title", "completed"))
with TRACER.start_as_current_span("redis_serialization"):
cache.set(key, json.dumps(tasks), timeout=5 * 60)
with TRACER.start_as_current_span("render_template") as render_span:
response = render(request, 'task_list.html', {'tasks': tasks, 'q': q})
return response
Смотрим спан:
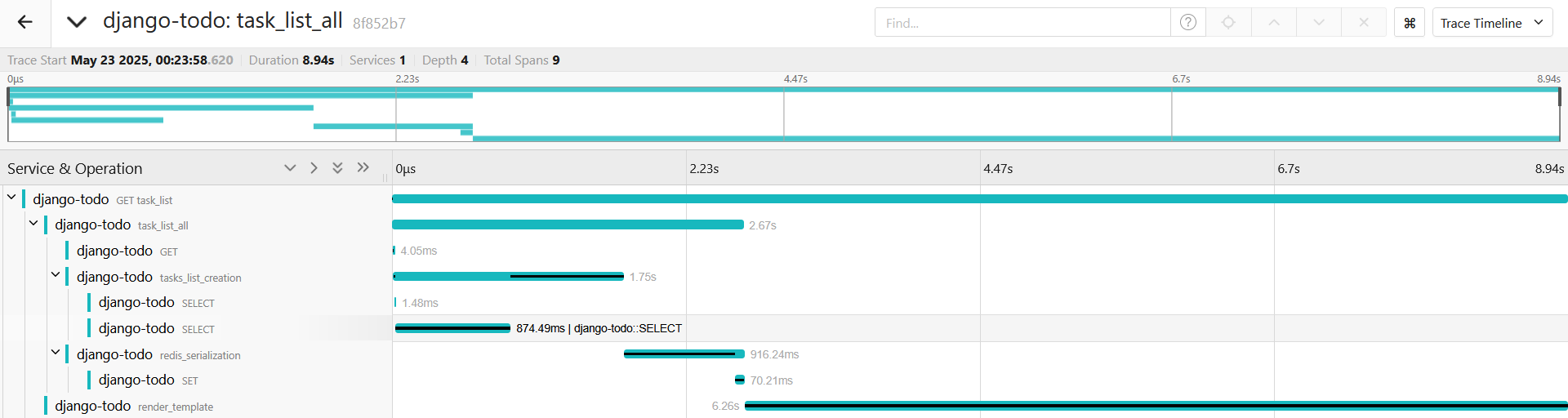
Не очень помогло, а в случае передачи списка в редис, так еще и хуже стало, пробуем orjson, добавляем в requirements.txt, добавляем его в requirements.txt:
orjson
Заменяем вызовы json.load, json.dumps на orjson.load, orjson.dumps, замеряем снова:
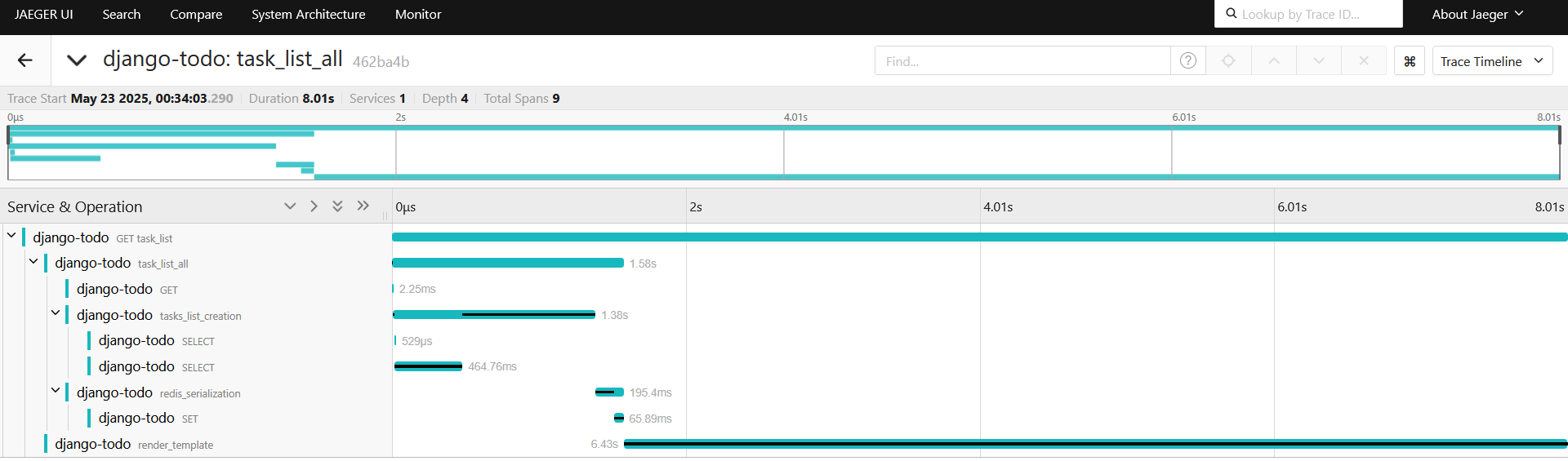
Создание списка после sql 815 мс, передача его в редис 129.51 мс, прирост производительности есть.
Повторно заходим на страницу, операция GET из Redis 206.93мс, десериализация 360.56мс

Попробуем закэшировать рендер страницы целиком, 6 секунд все таки:
from django.http import HttpResponse
def task_list(request):
q = request.GET.get("q", "").strip()
trace_name = "task_list_all" if not q else "task_list_search"
base_key = f"task_list::search::{hashlib.md5(q.encode()).hexdigest()}" if q else "task_list::all"
html_key = f"{base_key}::html"
with TRACER.start_as_current_span(trace_name):
cached_html = cache.get(html_key)
if cached_html:
return HttpResponse(cached_html)
# если нет HTML, проверим кэш с задачами
cached = cache.get(base_key)
if cached:
with TRACER.start_as_current_span("redis_deserialization"):
tasks = orjson.loads(cached)
else:
if q:
tasks = list(Task.objects.filter(title__icontains=q).values("id", "title", "completed"))
else:
with TRACER.start_as_current_span("tasks_list_creation"):
tasks = list(Task.objects.values("id", "title", "completed"))
with TRACER.start_as_current_span("redis_serialization"):
cache.set(base_key, orjson.dumps(tasks), timeout=5 * 60)
with TRACER.start_as_current_span("render_template"):
html = render(request, 'task_list.html', {'tasks': tasks, 'q': q}).content
cache.set(html_key, html, timeout=5 * 60)
return HttpResponse(html)
Смотрим спан, при первом вызове все без изменений, смотрим второй трейс:
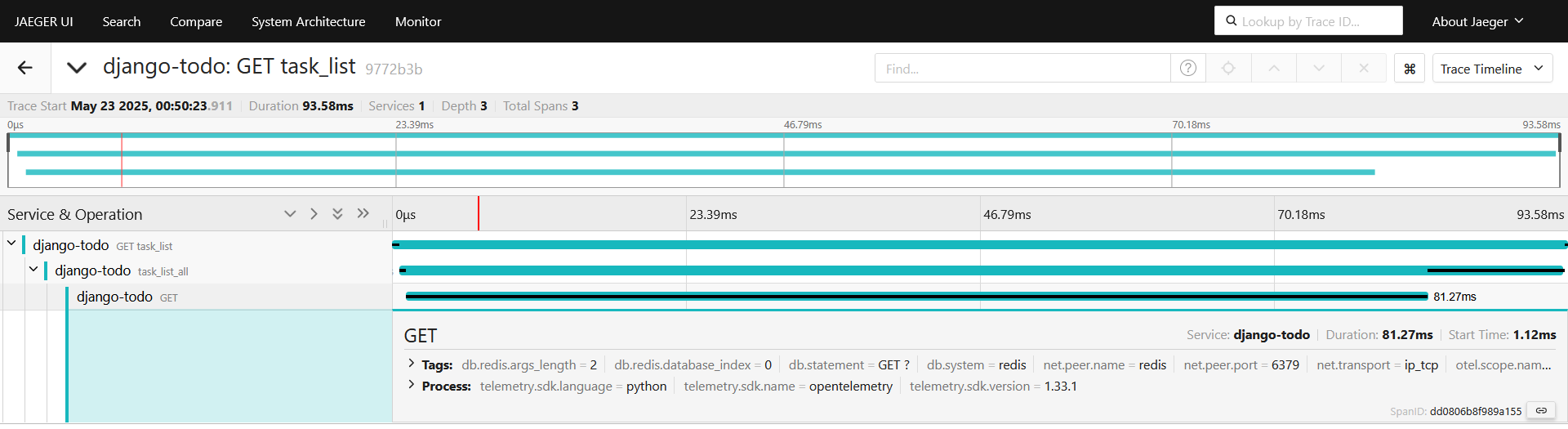
Спанов дочерних стало меньше, мы до них даже не доходим, отдаем сразу отрендеренный html, таким образом сократили до 93.58мс ответ демостенда.
